Скоро эта страница будет выглядеть по-новому Скоро эта страница будет выглядеть по-новому
|
Для автоматизации импорта данных в "Первую Форму" можно использовать готовые настройки. С их помощью можно импортировать задачи, учетные записи пользователей, элементы орг. структуры.
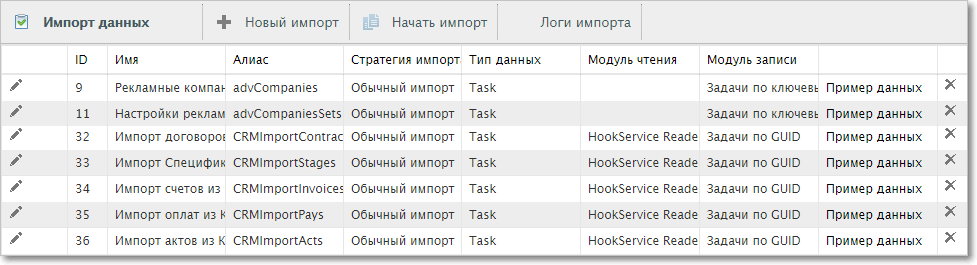
Список всех настроек импорта данных
Для импорта данных из нового источника сначала необходимо создать соответствующую настройку (1), а затем импортировать данные с использованием этой настройки (2).
Порядок действий для импорта данных из нового источника
Добавление и редактирование настройки импорта
С технической точки зрения в реализации импорта данных участвуют модуль чтения (считывает данные из источника) и модуль записи (записывает данные в "Первую Форму"). Модуль чтения передает в модуль записи три массива: Created, Updated, Deleted. В каждом массиве находятся объекты со строковым идентификатором UniqueID. В зависимости от внутренней реализации модуль записи разрешает конфликты уникальности данных и выполняет необходимые действия.
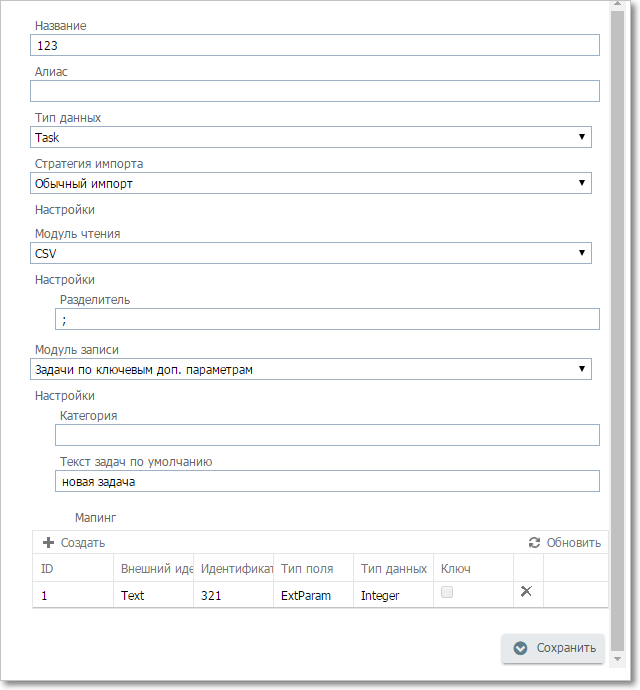
Для добавления новой настройки импорта нажмите кнопку Новый импорт. Откроется окно создания новой настройки:
Окно настроек импорта данных
Параметры настройки импорта данных
Название
|
Описание
|
Название
|
Название настройки в системе (любой текст. включая латинские и кириллические символы, цифры и пр.)
|
Алиас
|
Адрес для вызова внешними системами (включает только латинские буквы без пробелов).
Вызвать импорт можно через POST запрос вида
~/app/v1.0/api/DataSync/Import/NNNN?UserID=NN
где ~ — адрес приложения "Первая Форма", NNNN — алиас, указанный в настройках импорта, а NN — ID пользователя от имени которого запускается импорт (обычно это служебный пользователь Systemrobot с ID=3).
|
Тип данных
|
Тип данных, которые импортируются в систему.
Возможные значения:
•Task (задачи), •OrgStructureUnit (орг. единицы), •User (пользователи), •File (файлы). В заказных модулях импорта могут использоваться:
•ExtParam (ДП), •TableColumn (колонка ДП "Таблица"), •None |
Стратегия импорта
|
Выбор одной из реализованных стратегий.
Возможные значения:
•Обычный импорт (используется чаще всего), •Постраничный импорт (используется если объемы импортируемых данных большие) |
Модуль чтения
|
Выбор одного из реализованных модулей.
Возможные значения:
•CSV, •SQL, •Excel, •HookService Reader (для импорта из другого приложения "Первая Форма") |
Модуль записи
|
Выбор одной из стратегий записи.
Возможные значения:
•Задачи по номеру, •Задачи по ключевым доп. параметрам, •Задачи по GUID |
Маппинг
|
Соответствия между импортируемыми данными и объектами "Первой Формы", в которые эти данные записываются
|
После нажатия на кнопку Сохранить в таблице настроек появится новая запись. Вы можете отредактировать ее, нажав на иконку  в начале строки.
в начале строки.
Список настроек импорта данных
После сохранения для записи становятся доступны дополнительные настройки для стратегии импорта, модулей чтения и записи, а также настройка маппинга.
Дополнительные настройки импорта, которые становятся доступны после сохранения новой записи
В зависимости от стратегии импорта и от выбранного модуля чтения или записи настройки имеют свои особенности.
Стратегии импорта
Обычный импорт
|
Настройки стратегии импорта. Обычный импорт
(не имеет дополнительных настроек)
Работает для типов данных Task и TableColumn.
|
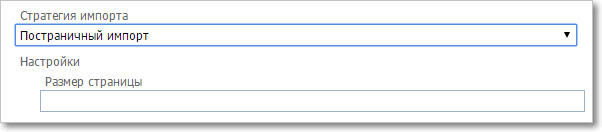
Постраничный импорт
|
Настройки стратегии импорта. Постраничный импорт
•Размер страницы — число элементов, которые будут прочитаны за одну операцию импорта Работает для типов данных Task, OrgStructureUnit, User и File.
|
Модули чтения
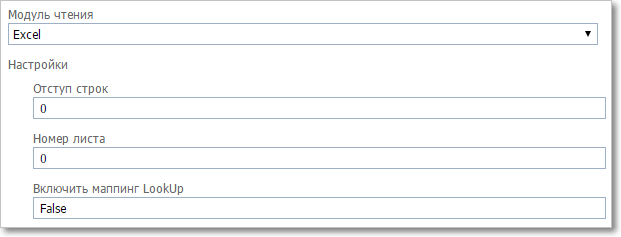
Для импорта из Excel
|
Настройки модуля чтения. Импорт из Excel
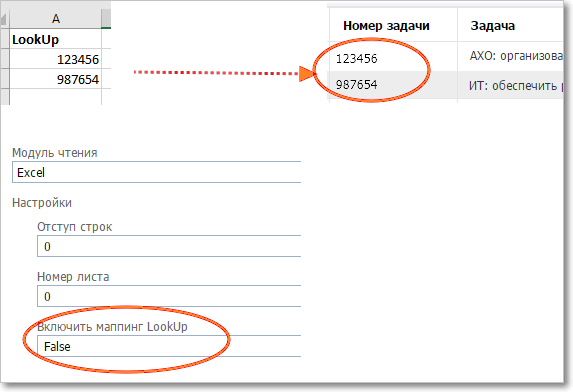
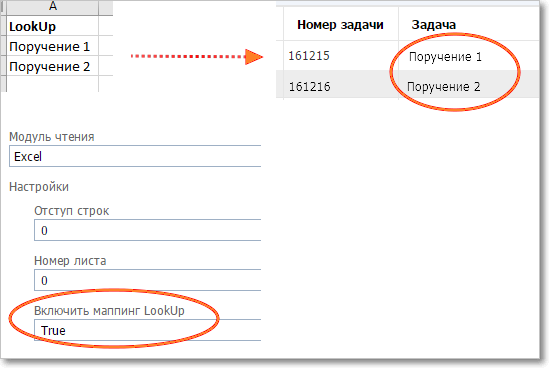
•Отступ строк — число строк вверху страницы, которые будут игнорироваться при импорте данных (например, "шапка" с названиями колонок) •Номер листа — номер листа в многостраничной книге Excel. Обратите внимание, что иногда листы могут отображаться в обратном порядке. Предпочтительнее импортировать данные из файлов Excel, содержащих только один лист •Включить маппинг LookUp — True\False. Если False, то предполагается, что в таблице Excel для ДП типа LookUp содержатся ID задач, на которые они ссылаются. Если True, то значение ДП типа LookUp считается строкой; для каждого значения будет выполнен поиск по тексту задач в категории, на которую настроен ДП, и если будет найдена задача с таким же текстом, то при импорте в задачу будет записана ссылка на нее. ВАЖНО: в настройках ДП LookUp должны быть включены все статусы задач.
|
Настройки импорта ДП Lookup по ID задачи
|
Настройки импорта ДП Lookup по тексту задачи
|
|
Для импорта из CSV
|
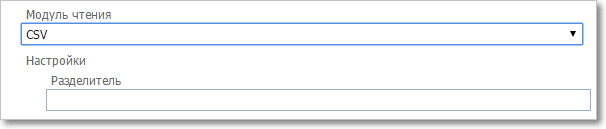
Настройки модуля чтения. Импорт из CSV
•Разделитель — символ-разделитель при перечислении значений Особенности импорта из CSV
1.Файл с данными должен содержать только те колонки, которые используются при импорте, и только в том порядке, как они настроены в маппинге. 2.Ключевое поле должно быть первой колонкой в исходном файле и первой строкой в настройках маппинга. 3.Первая строка файла с данными при импорте всегда игнорируется (предполагается, что она содержит названия столбцов). |
Для импорта из SQL
|
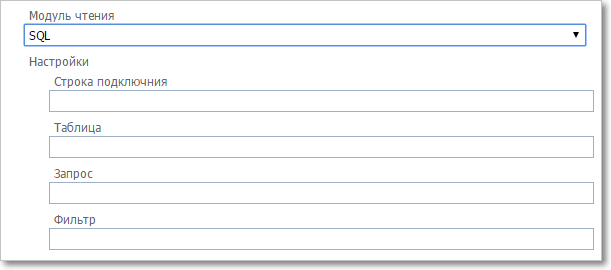
Настройки модуля чтения. Импорт из SQL
Могут быть указаны не все, а только нужные параметры:
•Строка подключения — строка подключения к БД вида: Data Source= <адрес сервера БД>,<порт>;Initial Catalog=<имя каталога>;Persist Security Info=True;User ID=<логин пользователя>;Password=<пароль пользователя>;Max Pool Size=2500;MultipleActiveResultSets=true
•Таблица — имя таблицы, из которой импортируются данные •Запрос — текст SQL-запроса для отбора данных для импорта •Фильтр — дополнительное условие отбора, например: object_id='123456' |
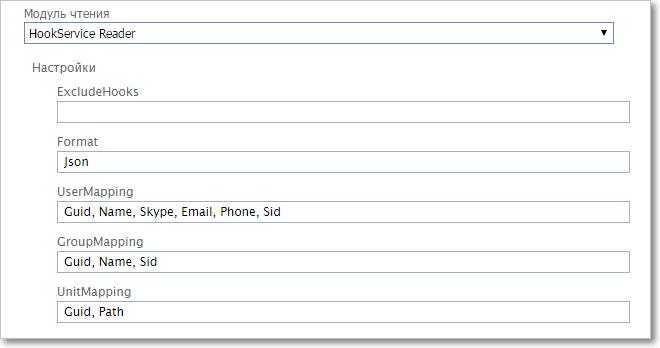
Для импорта из "Первой Формы"
|
Настройки модуля чтения. Импорт из "Первой Формы"
•ExcludeHooks — список названий сервисов отсылки событий, которые не должны реагировать на получение события по этому импорту (разделители списка — символы "," или ";" или ":"). Список указывается для предотвращения бесконечного цикла синхронизации между приложениями •Format — формат принимаемого сообщения (xml или json) •UserMapping — список параметров для сопоставления пользователей (разделители списка — символы "," или ";" или ":") •GroupMapping — список параметров для сопоставления групп (разделители списка — символы "," или ";" или ":") •UnitMapping — список параметров для сопоставления орг. единиц (разделители списка — символы "," или ";" или ":") В полях UserMapping, GroupMapping и UnitMapping параметры перечисляются в том порядке, в котором они используются для поиска подходящей записи в БД. Например, при сопоставлении пользователей (поле UserMapping) сначала выполняется поиск по Guid; если подходящий пользователь найден, то поиск останавливается, а если не найден, то выполняется поиск по имени (Name), и так далее.
|
Модули записи
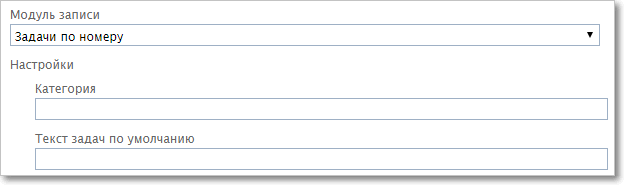
Задачи по номеру или Задачи по GUID
|
Настройки модуля записи. Поиск задачи по номеру или по GUID
•Категория — ID категории для импортируемых задач. •Текст задач по умолчанию — текст, который проставляется для импортируемых задач (например, Договор)
 Поиск задачи по GUID используется в том случае, если синхронизация данных с внешней системой происходит регулярно (т.е. повторяется не один раз) и необходимо обновлять ранее загруженные задачи. Использование номера задачи в этом случает невозможно, т.к. значение TaskID генерируется только при создании задачи в "Первой Форме", а во внешней системе этого параметра нет. Поиск задачи по GUID используется в том случае, если синхронизация данных с внешней системой происходит регулярно (т.е. повторяется не один раз) и необходимо обновлять ранее загруженные задачи. Использование номера задачи в этом случает невозможно, т.к. значение TaskID генерируется только при создании задачи в "Первой Форме", а во внешней системе этого параметра нет.
|
|
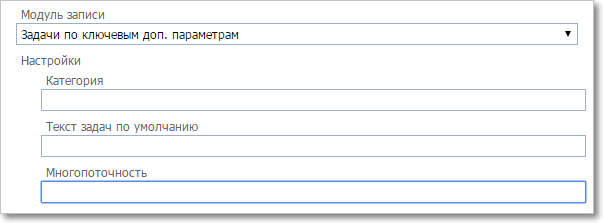
Задачи по ключевым доп.параметрам
|
Настройки модуля записи. Поиск задачи по ключевым ДП
•Категория — ID категории для импортируемых задач. •Текст задач по умолчанию — текст, который проставляется для импортируемых задач (например, Договор) •Многопоточность — True\False. При включенном режиме многопоточности обработка импортируемых задач будет производиться параллельно в произвольном порядке. Поэтому многопоточность необходимо отключать, если нужно сохранить оригинальный порядок данных. Количество потоков никак не ограничивается и определяется количеством доступных ресурсов. (Для разработчиков — используется метод Parallel.ForEach.) |
Импорт пользователей (UsersWriter)
Используются для импорта пользователей из внешней системы в "Первую Форму". В зависимости от источника данных, маппинг настраивается на колонки файла Excel или поля таблицы БД.
|
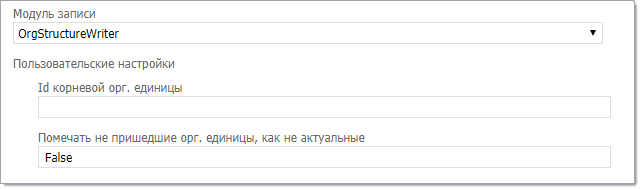
Импорт орг.единиц (OrgStructerWriter)
Используются для импорта орг. единиц из внешней системы в "Первую Форму". В зависимости от источника данных, маппинг настраивается на колонки файла Excel или поля таблицы БД.
Пользовательские настройки:
•Id корневой орг. единицы — ID орг. единицы, в рамках которой выполняется синхронизация. Если не указан — синхронизация выполняется для всей орг.структуры. •Помечать не пришедшие орг. единицы, как не актуальные — True\False. По умолчанию False. Режим True позволяет помечать неакутальными те орг. единицы, которые не пришли из внешнего источника данных.
Если для существующей орг. единицы не найдено соответствие в данных, пришедших из внешнего источника, то при включенном режиме (True) такая орг. единица помечается как неактуальная, а при выключенном режиме (False) сохраняет свое текущее состояние. Особенности синхронизации:
Маппинг орг.единицы выполняется по полю ExternalId. Если соответствие с орг.единицей найдено, то она обновляется, если не найдено — создается.
Маппинг родительской орг.единицы выполняется по полю ParentExternalId, внутри ветки с указанной корневой орг.единицей (родительская орг.единица также должна находиться внутри этой ветки).
Если родительская орг.единица указана и найдена, то она устанавливается как родительская для обновляемой\создаваемой орг. единицы;
если родительская орг. единица указана, но не найдена — у обновляемой орг. единицы родительская орг. единица не меняется (остается как было);
если родительская орг. единица не указана, а в настройках указан Id корневой орг. единицы, то эта корневая орг. единица назначается родительской для текущей;
если родительская орг. единица не указана и Id корневой орг. единицы не указан в настройках, то текущая орг. единица остается без родительской орг. единицы.
|
Полезные ссылки
Синхронизация с другими системами
Примеры настроек импорта