
Работа с данными в ДП типа "Таблица" осуществляется на уровне строк: если надо добавить или изменить значение в ячейке таблицы, то происходит обращение ко всей строке таблицы. Для работы со строками таблицы используются конструкции формата JSON.
Ячейка таблицы описывается конструкцией вида:
ID_колонки:{"First":ХХ,"Second":YY}
В ключе "First" (вместо XX) указывается вносимое значение. Его тип должен соответствовать типу колонки. При формировании строки значение должно преобразовываться к текстовому виду. Например, для числового значения — с помощью функции ВСтроку(). Текстовые значения должны быть заключены в двойные кавычки.
Ключ "Second" для большинства ячеек может не указываться (подробнее см. ниже).
Строка таблицы описывается как набор ячеек:
{"First":"ID_строки","Second":{ID_колонки:{"First":ХХ,"Second":YY},...,ID_колонки:{"First":ХХ,"Second":YY}}}
Перед описанием строки ставится знак операции: "+" для добавления строки, "-" для удаления строки или "=" для изменения значений.
Вся конструкция целиком представляет собой строку, поэтому она должна заключаться в одинарные кавычки и при ее формировании должен соблюдаться синтаксис работы со строками.
Двойные кавычки " необходимо экранировать символом обратного слеша \: '123:{"First":"начало \"ABC\" продолжение"}'. Символ обратного слеша \ необходимо повторять дважды: '123:{"First":"начало \\ продолжение"}'. Символ одинарной кавычки ' необходимо повторять дважды (в примере ниже подстрока АВС окружена одинарными кавычками, повторенными дважды): '123:{"First":"начало ''ABC'' продолжение"}'. Перенос строки \n \r экранировать не надо (перенос строки работает только для колонок "Большой текст", в режиме чтения перенос отображается как пробел, в режиме редактирования — как перенос): '123:{"First":"первая строка \n \r вторая строка"}' |
|---|
Добавление новой строки
При добавлении новой строки достаточно указать только те колонки, где в ячейках есть значения, пустые колонки можно пропустить. Поскольку при добавлении новой строки значение "ID_строки" не известно, оно не указывается. Массив с описаниями ячеек заключается в квадратные скобки [ ]. ID_колонки не берется в кавычки.
'+[{ID_колонки:{"First":ХХ,"Second":YY},...,ID_колонки:{"First":ХХ,"Second":YY}}]'

Внесение изменений в строку таблицы
При внесении изменений в строку можно указывать только те колонки, где значения изменяются. В остальных колонках значения останутся прежними. ID_строки берется в кавычки, ID_колонки — нет.
'={"First":"ID_строки","Second":{ID_колонки:{"First":ХХ},...,ID_колонки:{"First":ХХ}}}'
Удаление строки из таблицы
При удалении важен только ID строки, поэтому все остальное не указывается. ID_строки не берется в кавычки.
'-ID_строки'
Выпадающие списки
Ключ "Second" должен указываться только для ячеек типа "Выпадающий список". Для остальных типов этот ключ необязателен, поэтому может быть пропущен или равен "null".
Для выпадающих списков, которые формируются из таблицы, значение ключа "First" — это значение поля, указанного как "Колонка текста", а значение ключа "Second" — поля, указанного как "Колонка значения".
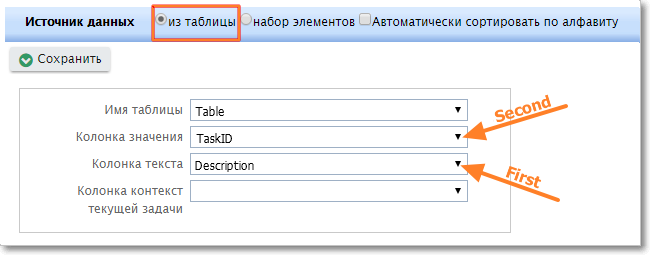
Ключи для выпадающего списка, который формируется из таблицы.
Для выпадающих списков, которые формируются из набора элементов, и значение ключа "First", и значение ключа "Second" — это значение из колонки Текст.
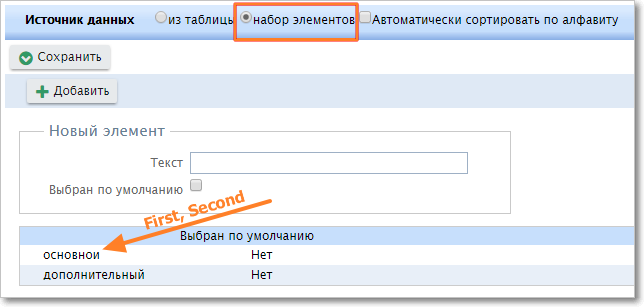
Ключи для выпадающего списка, который формируется из набора элементов.
Одновременное изменение (обновление) всех строк ДП "Таблица"
(может использоваться, например, при обмене данными с базами "1С:Предприятие")
Для одновременного обновления всех строк ДП "Таблица" могут использоваться два оператора: # и |. Эти операторы меняют исходное значение ДП "Таблица" на новое, переданное значение. Оба оператора работают примерно одинаково за исключением того, что оператор | сначала удаляет все строки из исходной таблицы, а потом создает их из переданных данных, а оператор # удаляет только те строки, которых нет в переданных данных, добавляет только те строки, которых нет в исходной таблице, и изменяет только те строки, которые присутствуют и в исходной, и в переданной таблице.
Формат записи для этих операторов одинаковый. ID_строки берется в кавычки, ID_колонки — нет.
'#{"ID_строки":{ID_колонки:{"First":ХХ},...,ID_колонки:{"First":ХХ}},...,{"ID_строки":{ID_колонки:{"First":ХХ},...,ID_колонки:{"First":ХХ}}}'
или
'|{"ID_строки":{ID_колонки:{"First":ХХ},...,ID_колонки:{"First":ХХ}},...,{"ID_строки":{ID_колонки:{"First":ХХ},...,ID_колонки:{"First":ХХ}}}'
|
|---|
|
|---|